

-
林分密度指标是衡量林木竞争的一个重要指标,确定合适的密度指标是开展林分密度研究的重要前提。许多学者从不同的角度出发提出了各种密度指标来衡量一个林分的密度情况,例如Reinek林分密度指数(SDI)[1]、Nilson密度(SD指数)[2]、优势高-营养面积比(Z指数)[3]、相对植距(RS指数)[4]以及每公顷株数(N)等。因此,选择合适的林分密度指标对于提高生长模型的应用以及模型精度有重要意义。
森林生长模型是实现森林质量精准提升的关键技术。在预估年生长量时,各学者提出了不同方法,包括固定生长率法、内插法[5]、迭代法[6]和可变生长率法[7]。固定生长率法是假设在森林的整个生长期内,林木的年生长率是固定不变的,显而易见,并不符合林木的生长规律,因为随着林分生长,用于预估模型中的林分因子和单木因子时刻都在发生变化,必定会对单木生长量乃至林分蓄积产生影响。Cao等[8]在迭代法的基础上提出可变生长率法,解决了以上存在的问题,且比迭代法更简单,计算用时更少。张雄清等[9]利用可变生长率法建立的单木生长模型考虑了林分因子(林分优势高、林分断面积)和单木因子(树高、胸径),比利用固定生长率法建立的模型误差更小,预测精度更高,更具代表性。之后,Zhang等[10]基于可变生长率法建立了林分断面积、林分平均直径和林分直径标准差模型。
林分蓄积量是评价生产力的一个重要指标,所以选择合适的林分密度指标来构建杉木(Cunninghamia lanceolata (Lamb.) Hook.)林分蓄积量模型就显得尤为重要。本研究基于可变生长率法构建杉木林分蓄积量生长模型,并在模型中引入不同林分密度指标,选出能够应用于杉木林分蓄积量模型中的最优林分密度指标,以期实现杉木林分蓄积量的精准预测。
-
样地设置在福建武夷山北部的邵武市,位于117°43′ E, 27°05′ N。地貌特征主要是高山和低丘陵地区,海拔为250~700 m,坡度为25°~35°,为亚热带季风气候,年平均温度17.7 ℃,1月平均温度6.8 ℃,7月平均温度28 ℃,最低极端气温为−7.9 ℃,年日照时间1 740.7 h,平均霜冻期为95 d。年降水量1 768 mm,年平均相对湿度为82%。气候条件适合杉木生长。
试验林使用1年生苗木于1982年造林,完全随机区组设计,分5种造林密度:A:2 m × 3 m(1 667 株·hm−2),B:2 m × 1.5 m(3 333 株·hm−2),C:2 m × 1 m(5 000 株·hm−2),D:1 m × 1.5 m(6 667 株·hm−2)和E:1 m × 1 m(10 000 株·hm−2)。每个样地大小为20 m × 30 m,每种造林密度均重复3次,总计15个样地。标记了一共4 800棵树,在冬季测量树高和胸径,从1984至1990年,每年进行1次测量;从1992年至2010年,每隔1或者2年进行1次测量。在每个样地中,选取最高的6株树,并计算其平均树高作为林分优势高。具体统计数据见表1。研究数据随机抽取60%用于模型构建,剩余40%用于模型验证。
表 1 杉木人工林林分和单木变量统计
Table 1. Summary statistics of stand and tree variables of Chinese fir plantation
变量
Attribute最小值
Min.最大值
Max.平均值
Mean标准差
Standard deviation林龄
Age/a4.0 28.0 14.3 7.6 株数
Number /(trees·hm−2)1 175 10 000 4 617 2 557 优势高
Dominant height/m2.9 26.9 12.7 6.1 胸径
Tree diameter/cm3.6 39 9.3 5.1 断面积
Basal area/(m2·hm−2)0.8 81.1 39.3 22.2 蓄积量
Stand volume/(m3·hm−2)0.9 518.0 204.3 144.2 -
利用常用的5种林分密度指标,分别是每公顷株数密度N、林分密度SDI指数、SD指数、优势高—营养面积比Z指数和相对植距RS指数构建杉木林分蓄积量生长模型。
-
(1) SDI指数
SDI指数是Reineke基于完满立木度提出的一种林分密度指标[1]。其优点是不仅能反映林地内的株数,而且能反映林木的大小,同时不受林龄和立地条件的影响,具有容易测算、使用简单的特点[11]。其数学表达式为:
$ SDI={N\left(\frac{D\mathrm{q}}{D0}\right)}^{\beta } $
(1) 式中:Dq为林分平方平均胸径cm;D0为林分标准直径,杉木一般取值20 cm;β为Reinek自稀疏系数。Sun等[12]认为杉木同龄林中林木的自然死亡率达到2%时才开始启动林分自稀疏,因此在剔除自稀疏死亡率小于2%的样本后,根据Reineke的自稀疏理论,对单位面积株数N和林分平均胸径Dq进行对数转化,即lnN和lnDq计算杉木自然稀疏线斜率β。据此分析,计算得到自然稀疏斜率β=−1.897 2。
(2) SD指数
根据Nilson[2]对林木之间的平均距离L和平方平均胸径Dq的定义,林分相对密度SD指数的公式如下:
$ L=\frac{100}{{N}^{1/2}} $
$ D\mathrm{q}=a + bL $
$ SD=N{\left(\frac{D0 + k}{D\mathrm{q} + k}\right)}^{2} $
(2) 式中:a,b为参数,k=−a,D0取值20 cm。
(3)优势高—营养面积比Z指数
张连金等[3]采用单位面积内株数与优势木的平均高来反映林分中林木的相对密度的大小。其表达式如下:
$ Z=\frac{N{H}_{\mathrm{d}}}{10\mathrm{ }000} $
(3) 式中: Hd为优势木平均高。该指数与林龄、立地指数等无关,计算相对较为简单。
(4) 相对植距RS指数
相对植距包含了林分优势高和每公顷株数,其表达式如下[11]:
$ RS=\frac{100}{{N}^{1/2}{H}_{\mathrm{d}}} $
(4) -
本研究选取了优势高-营养面积比Z指数、每公顷株数密度N、Reineke密度指数SDI、Nilson密度SD指数和相对植距RS构建杉木林分蓄积量模型;
$\begin{array}{l} {M}_{2}={M}_{1} + \mathrm{e}\mathrm{x}\mathrm{p}(\left({\alpha }_{1} + {x}_{1}*{z}_{1} + {x}_{2}*{z}_{2} + {x}_{3}*\right. \\ \left.{z}_{3} + {x}_{4}*{z}_{4}\right) + {\alpha }_{2}*\dfrac{{A}_{1}}{\mathrm{ln}\left({H\mathrm{d}}_{1}\right)} + {\alpha }_{3}*{K}_{1}) \end{array}$
(5) 式子中:M1,M2分别为第1期和第2期的林分蓄积量;
A1为第1期的林分年龄;
Hd1第1期的林分平均优势高;
K1为第1期时的5种林分密度指标,包括:优势高-营养面积比Z指数,株数N,林分密度指数SDI,林分密度SD指数,相对植距RS指数;
x1~x4,α1~α3为模型参数;
z1~z4为5种不同造林密度设置的哑变量(造林密度1 667 株·hm−2:z1=1, z2=z3=z4=0;造林密度3 333 株·hm−2:z2=1, z1=z3=z4=0;造林密度5 000 株·hm−2:z3=1, z1=z2=z4=0;造林密度6 667 株·hm−2:z4=1, z1=z2=z3=0;造林密度10 000 株·hm−2:z1=z2=z3=z4=0)。
由于调查的间隔并不都是1年1次,因此为了提高模型的预测精度,可变生长率法被引入到本研究中。可变生长率法考虑间隔期内,林分优势高的变化引起的林分蓄积量生长的变化。杉木林分蓄积量年生长模型利用递归的方式推导过程如下:
(t + 1)年时:
$\begin{split} & {M}_{t + 1}={M}_{t} + \mathrm{e}\mathrm{x}\mathrm{p}(\left({\alpha }_{1} + {x}_{1}*{z}_{1} + {x}_{2}*{z}_{2} + {x}_{3}*{z}_{3} +\right.\\ & \left.{x}_{4}*{z}_{4}\right) + {\alpha }_{2}*\frac{{A}_{t}}{\mathrm{ln}\left({Hd}_{t}\right)} + {\alpha }_{3}*{K}_{t} ) \end{split} $
(6) (t + 2)年时:
$ \begin{split} & {M}_{t + 2}={M}_{t + 1} + \mathrm{e}\mathrm{x}\mathrm{p}(\left({\alpha }_{1} + {x}_{1}*{z}_{1} + {x}_{2}*{z}_{2} + {x}_{3}*{z}_{3} +\right.\\ &\left.{x}_{4}*{z}_{4}\right) + {\alpha }_{2}*\frac{{A}_{t + 1}}{\mathrm{ln}\left({Hd}_{t + 1}\right)} + {\alpha }_{3}*{K}_{t + 1}) \end{split} $
(7) $\vdots $
(t + q)年时:
$\begin{split} & {M}_{t + q}={M}_{t + q-1} + \mathrm{e}\mathrm{x}\mathrm{p}(\left({\alpha }_{1} + {x}_{1}*{z}_{1} + {x}_{2}*{z}_{2} + {x}_{3}*{z}_{3} +\right.\\ &\left. {x}_{4}*{z}_{4}\right) + {\alpha }_{2}*\frac{{A}_{t + q-1}}{\mathrm{ln}\left({Hd}_{t + q-1}\right)} + {\alpha }_{3}*{K}_{t + \mathrm{q}-1} \end{split}$
(8) 式中,t为调查年,q为调查间隔期。
研究中构建的杉木优势高模型形式如下:
$\begin{array}{c} {Hd}_{2}=\mathrm{e}\mathrm{x}\mathrm{p}\left(\dfrac{{A}_{1}}{{A}_{2}}*\mathrm{ln}\left({Hd}_{1}\right) + \left(1-\dfrac{{A}_{1}}{{A}_{2}}\right)*\left({\beta }_{1} + \right.\right.\\ \left.\left.{\beta }_{2}*\dfrac{{A}_{1}}{{Hd}_{1}}\right)\right) \end{array} $
(9) 其中β1、β2为待估参数。
本研究中, 杉木林分蓄积量模型的参数估计均利用 SAS中非线性回归模块来完成。利用可变生长率法估计模型参数时, 应用了循环运算。
-
林分优势高模型和林分蓄积生长模型通过统计量平均绝对偏差(MAD)、均方根误差( RMSE)和决定系数(R2) 进行评价。
-
杉木林分优势高模型的参数估计结果以及模型的均方根误差、决定系数见表2。结果表明,模型的参数估计值均为有效值,并且模型的决定系数很高,达到了0.953 9,均方根误差RMSE较小,为1.343 1。因此模型估计得到的林分优势高是可信的,可以用于构建杉木林分蓄积量模型。
表 2 杉木林分优势高模型的参数估计、标准误差、决定系数及均方根误差
Table 2. Parameter estimates and model evaluation of stand dominant height of Chinese fir
参数
Parameter估计值
Estimate标准误差
Standard dev. error决定系数
R2均方根误差
RMSEβ1 1.583 2 0.360 1 0.953 9 1.343 1 β2 1.470 1 0.325 3 分别用5种不同林分密度指标,利用可变生长率法建立了6种杉木林分蓄积量年生长模型,其中包括一种不含密度指标的生长模型。参数估计和标准误差及模型评价见表3。从表3中可以看到,5类含有密度指标的模型决定系数R2均在0.979以上,模型精确度较高,且大于不含密度指标的对照组模型(模型决定系数为0.972 8)。林分密度对于杉木蓄积量具有不可忽视的影响,因此将林分密度指标引入杉木林分蓄积量模型可以提升模型精确度,优化模型表现。
表 3 不同林分密度指标应用于杉木林分蓄积量模型的参数估计及模型评价
Table 3. Parameter estimation and model evaluation of stand volume model with different density indices
密度指标
Density
index参数
Parameter估计值
Estimate标准误差
Deviation
error决定
系数
R2平均绝对
偏差
MAD均方根
误差
RMSE优势高
营养面积
Zα1 2.591 9 0.313 7 0.979 3 10.452 5 20.651 2 α2 −0.255 7 0.044 3 α3 0.109 1 0.038 2 x1 1.086 1 0.338 1 x2 0.860 4 0.288 0 x3 0.644 9 0.236 0 x4 0.645 0 0.205 6 每公顷
株数
Nα1 −0.066 0 1.316 1 0.979 9 10.268 7 20.363 4 α2 −0.085 8 0.031 0 α3 0.000 3 0.000 1 x1 2.892 5 1.001 7 x2 2.281 8 0.808 9 x3 1.787 2 0.627 9 x4 1.334 6 0.441 5 相对植距
RSα1 4.589 9 0.369 5 0.979 9 10.046 1 20.369 4 α2 −0.300 8 0.047 4 α3 −3.354 2 2.107 2 x1 0.650 9 0.199 8 x2 0.453 9 0.188 1 x3 0.342 7 0.182 2 x4 0.452 2 0.177 5 林分密
度指数
SDIα1 3.440 2 0.236 3 0.979 4 10.431 1 20.630 9 α2 −0.326 2 0.061 4 α3 0.000 5 0.000 2 x1 0.721 9 0.228 7 x2 0.524 8 0.204 4 x3 0.418 8 0.192 7 x4 0.472 4 0.183 1 Nilson密
度指数
SDα1 3.825 1 0.259 6 0.979 0 10.613 2 20.811 7 α2 −0.344 3 0.075 5 α3 0.000 5 0.000 2 x1 0.448 3 0.188 8 x2 0.335 0 0.189 9 x3 0.289 9 0.190 2 x4 0.404 2 0.185 2 不含密
度指标
No densityα1 3.512 5 0.038 8 0.972 8 10.925 1 21.123 1 α2 −0.180 5 0.001 9 x1 0.379 9 0.190 4 x2 0.330 8 0.194 5 x3 0.310 9 0.195 5 x4 0.417 3 0.190 8 从模型决定系数方面来看,所有模型的R2数值由高到低顺序为:包含每公顷株数N的林分蓄积量模型(0.979 9)、相对植距模型(0.979 9)、林分密度指数SDI模型(0.979 4)、优势高营养面积比Z模型(0.979 3)、Nilson密度指数模型(0.979 0)以及不含密度指标模型(0.972 8)。除去因为参数估计异常而被舍弃的2号和3号模型,杉木林分蓄积量模型中表现最好的是以林分密度指数SDI为密度指标的模型。同时,SDI模型也取得了最小的平均绝对偏差和均方根误差。因此,从本研究结果中可以认为,林分密度指数SDI模型是估计杉木林分蓄积量的最佳模型。而不含密度指数模型则是表现最差的林分蓄积量模型,这也说明了在拟合和估计杉木林分蓄积量时,缺少密度指数将会影响模型的准确度。SD指数模型也因为在所有密度指数模型中表现最差,在估计杉木林分蓄积方面成为最不适合的密度指标。我们还发现,根据哑变量参数的估计值可得,在低造林密度(1 667~3 333 株·hm−2),林分蓄积生长量要大于中高造林密度的林分(5 000~10 000 株·hm−2)。
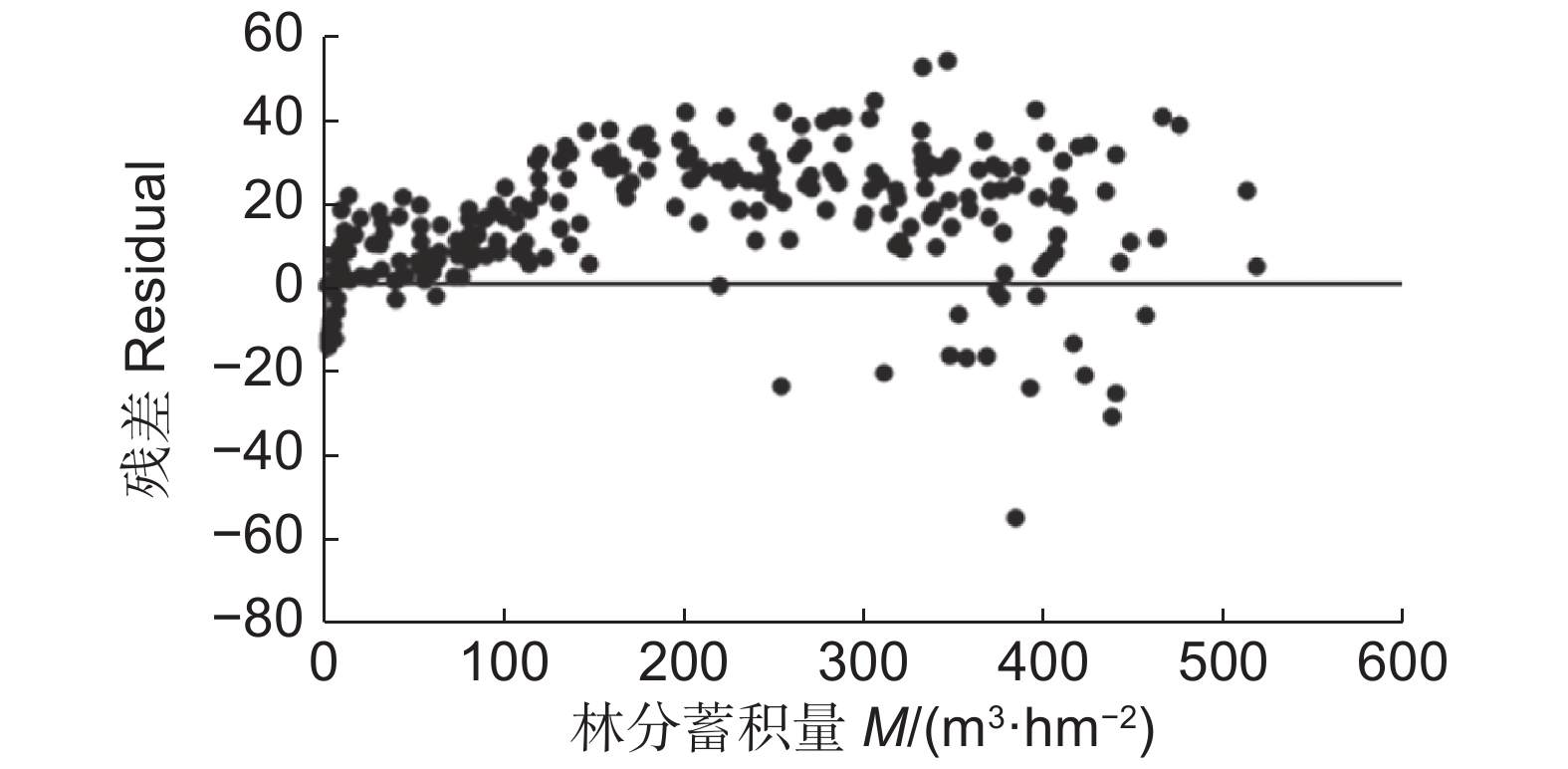
基于研究得到的预估杉木林分蓄积量的最佳模型,SDI模型,得到了模型残差分布图(图1)。从图1可以看到,都倾向于低估杉木的林分蓄积量。在林分蓄积量处于0~100 m3·hm−2的时候,残差点基本分布于0~−20的范围内;当实际林分蓄积量达到100 m3·hm−2以上时,残差点分布范围则有所扩大,基本上均匀分布在−10~−50 m3·hm−2的区间中。当然在实际林分蓄积量处于1~10 m3·hm−2和较大蓄积的时候,模型也有少量高估蓄积量的情况发生。
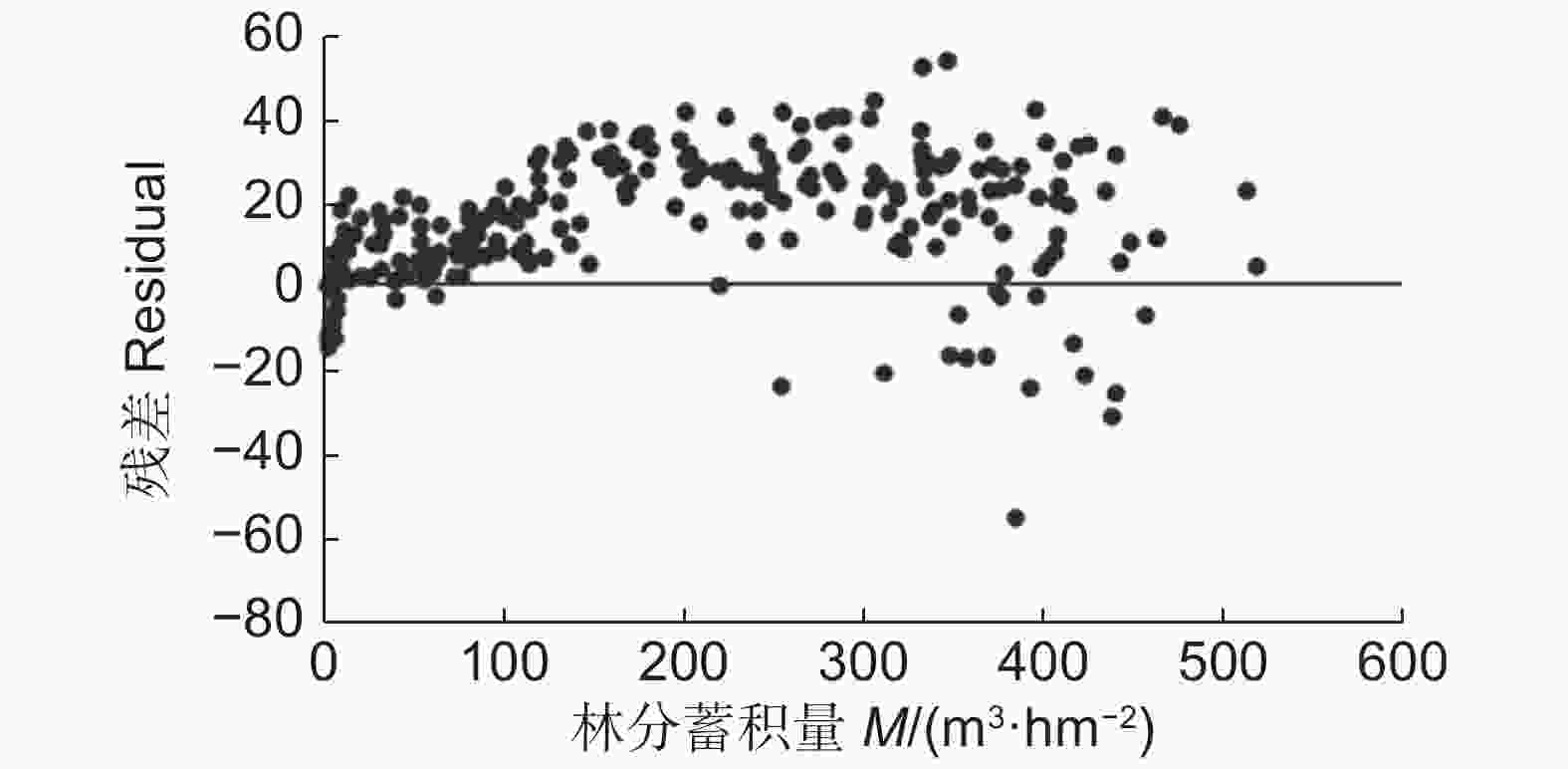
图 1 包含SDI密度指数的林分蓄积量模型的残差分布
Figure 1. Residual distribution of stand volume growth model including density index SDI
-
林分密度是林分生长模型预估的一个重要指标。不同的密度指标其应用的范围不一样,因此也受到了不同学者的争议。冉啟香等[13]在对北京地区油松(Pinus tabuliformis Carr.)林分蓄积生长模型研究的过程中指出,选用不同的密度指标构建模型会直接影响模型的预估效果,同时对每公顷胸高断面积(BA)、每公顷株数(N)、林分密度指数(SDI)等不同林分密度指标进行比较,最终得出用每公顷胸高断面积(BA)作为密度指标预估林分蓄积量生长模型时效果更好。张雄清等[14]利用林分株数密度N作为密度指标构建杉木林分蓄积量模型,并且模型的精度也较高。此外,许多学者在研究林分生长时也经常将林分密度指数SDI当作较好的密度指标纳入模型。吴宏炜等[15]基于福建湿地松(Pinus elliottii Engelm.)人工林调查数据,选取林分密度指数SDI构建湿地松生长模型,取得了较好的模型精确度。由此可以看出,选取合适的林分密度指标构建林分蓄积量模型很有必要。
但是对于SDI指数,争议较多的还是自然稀疏线斜率是否为−1.605。多数学者认为自然稀疏线斜率不是固定不变−1.605,而是随着树种、初始密度、立地以及气候的变化而变化[16-19]。Pretzsch和Biber[20]在构建挪威云杉(Picea abies (L.) Karst.)林分生长收获表时发现,用固定的−1.605斜率会导致SDI指数偏差,进而影响收获表的准确性。Zhang 等[21]基于气候敏感的林分密度指数SDI构建了杉木林分生长模型,发现该SDI指数很好地反映了密度的变化情况,使得林分生长模型精度得到提高。总之,基于我们的研究,对于杉木林分蓄积量建模预测,结果显示林分密度指数SDI为最佳的密度指标。同时,密度效应在杉木林分蓄积量生长中起到了很重要的作用,不含有密度指标的模型将在精度和预测能力上有所降低。
此外,对于定期(不定期)的调查数据,如何分析并构建年生长量模型对于精准预测很关键。近年来,基于已有的连续调查数据,通常用固定生长率法,其前提是假设在整个生长期,林分的年生长量不变,常用定期平均生长量来代替年生长量[11]。很明显该方法并不符合林分的实际生长规律。因为随着森林的演替过程,一些林分的特征(立地,年龄,林分竞争等)都会随着林龄变化而变化,因此也必然会导致林分的年生长量也发生变化。之后Ochi和Cao[22]提出利用可变生长率法建立林分年生长量相容性模型,得到了很好的拟合结果。之后张雄清等[23]基于北京山区油松定期调查数据,运用可变生长率法构建了北京油松全林分年生长模型。模型结果显示,利用可变生长率法构建的油松生长模型更加符合其生长规律,同时解决了模型在预测油松生长阶段中的无偏性,提升了模型预测性能。
-
基于可变生长率法,建立了含5种林分密度指标的杉木林分蓄积年生长模型,含有密度指标的模型决定系数R2均在0.979以上,精度高于不含密度指标的对照组模型。从模型的参数估计和模型精度上来看,精度最高的是包含每公顷株数密度N和相对植距RS的林分蓄积量模型。但由于这两个模型中的密度指标的参数估计不显著,模型表现不稳定,因此不适宜预测。而包含林分密度指数SDI的蓄积量模型相较于优势高营养面积比Z、Nilson密度SD指数和不含有密度指标的蓄积量模型,取得了最大的R2和最小的均方根误差和平均绝对误差,因此SDI指数在本研究中是建立杉木林分蓄积量模型中最好的密度指标。其次,本研究还发现在低造林密度(1 667~3 333 株·hm−2),林分蓄积生长量要大于中高造林密度的林分(5 000~10 000 株·hm−2)。
不同林分密度指标在杉木林分蓄积量模型的应用研究
Develop Annual Stand Volume Growth Model of Chinese fir Including Different Stand Density Indices
-
摘要:
目的 林分密度是反映单木林分中林木株树和竞争的一个重要指标,构建林分生长与收获模型的一个重要变量。选择合适的林分密度指标来构建杉木林分蓄积量模型,提高林分预测精度。 方法 以福建邵武杉木(Cunninghamia lanceolata)人工林密度长期试验林28 a连续观测数据为依据,基于可变生长率法,建立了含5种林分密度指标的杉木林分蓄积年生长模型。 结果 模型决定系数R2均在0.979以上,精度高于不含密度指标的对照组模型。在包含密度指标的模型中,精度最高的为每公顷株数N密度模型,其次是相对植距RS密度模型,但是这两个模型参数估计不显著而被舍弃。所有模型的R2数值由高到低顺序为:每公顷株数N林分蓄积量模型(0.979 9)、相对植距模型(0.979 9)、林分密度指数SDI模型(0.979 4)、优势高营养面积比Z模型(0.979 3)、Nilson密度指数模型(0.979 0)以及不含密度指标模型(0.972 8)。 结论 除去N指标和RS指标模型,杉木林分蓄积量模型中表现最好的是以林分密度指数SDI为密度指标的模型。其次,还发现在低造林密度(1 667~3 333 株·hm−2)林分,蓄积生长量要大于中高造林密度(5 000~10 000 株·hm−2)的林分。 -
关键词:
- 杉木
- / 林分密度指标
- / 林分蓄积量年生长模型
- / 可变生长率法
Abstract:Objective Stand density is an important index to reflect the number and competition in a stand. It plays a critical role in stand growth models. It is of great significance to analyze the application value of stand density index in stand volume growth model for accurate prediction. Method Based on the 28 years continuous observation data of the spacing trials of Chinese fir (Cunninghamia lanceolata) plantation in Shaowu, Fujian Province, the annual growth model of stand volume of Chinese fir including five different density indices respectively were developed based on the variable rate method, as well as the model without stand density index. Result The R2 values of the models including density indices were all larger than 0.979, and the model performance was higher than that of the model without density index. Among the five models including stand density indices, the model including living number of trees per ha (N) had the largest value of R2, followed by the model with RS density. However, the two models are not feasible because of the parameter estimates of stand density index were not significant. The R2 values of all models from high to low were: stand volume model including N (0.979 9), relative spacing RS (0.979 9), stand density index SDI (0.979 4), dominant high nutrient area ratio Z (0.979 3), Nilson density index model (0.979 0) and without density index (0.972 8). Conclusion Accounting for significance of the parameter estimate, the model with stand density index SDI performed the best in the stand volume model of Chinese fir. In addition, stand volume in stands of planting density (1 667 ~ 3 333 trees·hm−2) was larger than the denser stands (5 000 ~ 10 000 trees·hm−2). -
图 1 包含SDI密度指数的林分蓄积量模型的残差分布
Figure 1. Residual distribution of stand volume growth model including density index SDI
表 1 杉木人工林林分和单木变量统计
Table 1. Summary statistics of stand and tree variables of Chinese fir plantation
变量
Attribute最小值
Min.最大值
Max.平均值
Mean标准差
Standard deviation林龄
Age/a4.0 28.0 14.3 7.6 株数
Number /(trees·hm−2)1 175 10 000 4 617 2 557 优势高
Dominant height/m2.9 26.9 12.7 6.1 胸径
Tree diameter/cm3.6 39 9.3 5.1 断面积
Basal area/(m2·hm−2)0.8 81.1 39.3 22.2 蓄积量
Stand volume/(m3·hm−2)0.9 518.0 204.3 144.2  下载: 导出CSV
下载: 导出CSV
表 2 杉木林分优势高模型的参数估计、标准误差、决定系数及均方根误差
Table 2. Parameter estimates and model evaluation of stand dominant height of Chinese fir
参数
Parameter估计值
Estimate标准误差
Standard dev. error决定系数
R2均方根误差
RMSEβ1 1.583 2 0.360 1 0.953 9 1.343 1 β2 1.470 1 0.325 3
下载: 导出CSV
表 3 不同林分密度指标应用于杉木林分蓄积量模型的参数估计及模型评价
Table 3. Parameter estimation and model evaluation of stand volume model with different density indices
密度指标
Density
index参数
Parameter估计值
Estimate标准误差
Deviation
error决定
系数
R2平均绝对
偏差
MAD均方根
误差
RMSE优势高
营养面积
Zα1 2.591 9 0.313 7 0.979 3 10.452 5 20.651 2 α2 −0.255 7 0.044 3 α3 0.109 1 0.038 2 x1 1.086 1 0.338 1 x2 0.860 4 0.288 0 x3 0.644 9 0.236 0 x4 0.645 0 0.205 6 每公顷
株数
Nα1 −0.066 0 1.316 1 0.979 9 10.268 7 20.363 4 α2 −0.085 8 0.031 0 α3 0.000 3 0.000 1 x1 2.892 5 1.001 7 x2 2.281 8 0.808 9 x3 1.787 2 0.627 9 x4 1.334 6 0.441 5 相对植距
RSα1 4.589 9 0.369 5 0.979 9 10.046 1 20.369 4 α2 −0.300 8 0.047 4 α3 −3.354 2 2.107 2 x1 0.650 9 0.199 8 x2 0.453 9 0.188 1 x3 0.342 7 0.182 2 x4 0.452 2 0.177 5 林分密
度指数
SDIα1 3.440 2 0.236 3 0.979 4 10.431 1 20.630 9 α2 −0.326 2 0.061 4 α3 0.000 5 0.000 2 x1 0.721 9 0.228 7 x2 0.524 8 0.204 4 x3 0.418 8 0.192 7 x4 0.472 4 0.183 1 Nilson密
度指数
SDα1 3.825 1 0.259 6 0.979 0 10.613 2 20.811 7 α2 −0.344 3 0.075 5 α3 0.000 5 0.000 2 x1 0.448 3 0.188 8 x2 0.335 0 0.189 9 x3 0.289 9 0.190 2 x4 0.404 2 0.185 2 不含密
度指标
No densityα1 3.512 5 0.038 8 0.972 8 10.925 1 21.123 1 α2 −0.180 5 0.001 9 x1 0.379 9 0.190 4 x2 0.330 8 0.194 5 x3 0.310 9 0.195 5 x4 0.417 3 0.190 8
下载: 导出CSV
-
[1] Reineke L H. Perfecting a stand-density index for even-aged forests[J]. Journal of Agricultural Research, 1933, 46(7): 627-638. [2] Nilson A. Modeling dependence between the number of trees and mean tree diameter of stand, stand density and stand sparsity[C]// Cieszewski C J, Strub M. Second International Conference on Forest Measurement and Quantitative Methods and Management & the 2004 Southern Mensurationists Meeting 15–18 June 2004 Hot Springs, Arkansas, USA. University of Georgia, Athens, USA, 74–94. 2006. [3] 张连金, 惠刚盈, 孙长忠. 不同林分密度指标的比较研究[J]. 福建林学院学报, 2011, 31(3):257-261. doi: 10.3969/j.issn.1001-389X.2011.03.014 [4] Daniels R F, Burkhart H E. An integrated system of forest stand models[J]. Forest Ecology and Management, 1989, 23: 159-177. [5] Mcdill M E, Amateis R L. Fitting discrete-time dynamic models having any time interval[J]. Forest Science, 1993, 39(3): 499-519. [6] Cao Q V. Prediction of annual diameter growth and survival for individual trees from periodic measurements[J]. Forest Science, 2000, 46(1): 127-131. [7] Cao Q V. Annual tree growth predictions based on periodic measurements[R]. IUFRO Symposium on Statistics and Information Technology in Forestry. Blacksburg, VA, 2002: 7-13. [8] Cao Q V, Li S, Mcdill M E. Developing a system of annual tree growth equations for the loblolly pine-shortleaf pine type in Louisiana[J]. Canada Journal Forest Research, 2002, 32(11): 2051-2059. doi: 10.1139/x02-128 [9] 张雄清, 雷渊才. 可变生长率法和固定生长率法在单木年生长预测中的比较研究[J]. 林业科学研究, 2009, 22(6):824-828. doi: 10.3321/j.issn:1001-1498.2009.06.013 [10] Zhang X, Lei Y, Cao Q V. Compatibility of stand basal area predictions based on forecast combination[J]. Forest Science, 2010, 56(6): 552-557. [11] 孟宪宇. 测树学(第二版)[M]. 北京: 中国林业出版社, 1996. [12] Sun H, Zhang J, Duan A, et al. Estimation of the self-thinning boundary line within even-aged Chinese fir (Cunninghamia lanceolata ( Lamb. ) Hook. ) stands: Onset of self-thinning[J]. Forest Ecology and Management, 2011, 261(6): 1010-1015. doi: 10.1016/j.foreco.2010.12.019 [13] 冉啟香, 邓华锋, 吕常笑, 等. 油松林分断面积与蓄积量生长模型研究[J]. 西北林学院学报, 2016, 31(5):217-223. doi: 10.3969/j.issn.1001-7461.2016.05.36 [14] 张雄清, 张建国, 段爱国. 基于单木水平和林分水平杉木兼容性林分蓄积量模型的研究[J]. 林业科学, 2014, 50(1):82-87. [15] 吴宏炜, 田 意, 黄光灿, 等. 基于非线性度量误差的湿地松生长模型[J]. 林业资源管理, 2019(6):71-76. [16] Charr M I, Seynave F, Morneau M, et al. Significant differences and curvilinearity in the self-thinning relationships of 11 temperate tree species assessed from forest inventory data[J]. Annals of Forest Science, 2012, 69: 195-205. doi: 10.1007/s13595-011-0149-0 [17] Comeau P G, White M, Kerr G, et al. Maximum density–size relationships for Sitka spruce and coastal Douglas-fir in Britain and Canada[J]. Forestry, 2010, 83(5): 461-468. doi: 10.1093/forestry/cpq028 [18] Weiskittel A, Gould P, Temesgen H. Sources of variation in the self-thinning boundary line for three species with varying levels of shade tolerance[J]. Forest Science, 2009, 55(1): 84-93. [19] Zhang X, Lu L, Cao Q V, et al. Climate sensitive self-thinning trajectories of Chinese fir plantations in south China[J]. Canadian Journal of Forest Research, 2018, 48: 1388-1397. doi: 10.1139/cjfr-2018-0168 [20] Pretzsch H, Biber P. A re-evaluation of Reineke’s rule and stand density index[J]. Forest Science, 2005, 51(4): 304-320. [21] Zhang X, Cao Q V, Lu L, et al. Use of modified reineke's stand density index in predicting growth and survival of Chinese fir plantations[J]. Forest Science, 2019, 65(6): 776-783. doi: 10.1093/forsci/fxz033 [22] Ochi N, Cao Q V. A comparison of compatible and annual growth models[J]. Forest Science, 2003, 49(2): 285-290. [23] 张雄清, 雷渊才. 基于定期调查数据的全林分年生长预测模型研究[J]. 中南林业科技大学学报, 2010, 30(40):69-74. -
 点击查看大图
点击查看大图
图(1) / 表(3)
计量
- 文章访问数: 3110
- HTML全文浏览量: 2317
- PDF下载量: 88
- 被引次数: 0












