

-
立地质量评价是对森林立地的宜林性或潜在生产力判断或预测的基础工作 [1],立地指数是一种最普遍的评价森林立地质量的方法[2-3],分析某树种林分基准年龄时对应的林分优势高可用于分析森林立地生产潜力的基础[4]。除了根据优势高与年龄指标,还能够通过样地实测值和收获表蓄积量估算获得立地指数[5]。但由于立地条件的差异性或多样性,基于优势高-年龄的导向曲线模拟精度往往较低,同一树种在不同区域的立地指数估计结果随立地质量的不同而存在显著差异。因此,很多学者在评价立地质量时,优先分析环境要素(气候、植被、地形等)与立地指数的关系,得到包含环境因子的立地指数函数关系[6-7]。也有学者采用树高-年龄分级哑变量的方法,用样地林木平均高划分等级代替立地因子评价立地质量[8]。这些方法虽然提高了立地指数建模精度,但关于环境因子在模型中的表达仍需进一步探索。
目前,如何建立立地指数模型成为描述森林立地质量的重点和中心问题。研究指出有单形和多形两种关系,其中多形立地指数曲线结合优势木平均高和其他反映立地条件因子,共同评定立地质量[9-11]。最常用的2种拟合方法为固定基准年龄的静态方程和可变基准年龄的动态方程,前者依赖于选定的基准年龄,后者局限于严格的数据要求[12]。而混合效应模型是一种最常用的处理局部变异性的建模方法[13-14]。对于不同立地类型的优势高生长,混合模型不仅能够描述整体变化的平均趋势,还能够给出协方差和方差等相关数据以了解个体特点[15-16]。虽然在构建立地指数模型时,相关文献运用数量化方法I [17-18],然而该方法前提是固定效应,如果考虑随机效应,该方法不适用。
鉴于此,本研究以湖南丘陵平原区杉木(Cunninghamia lanceolata (Lamb.) Hook.)人工林为研究对象,首先利用数量化方法I确定影响杉木优势高生长的显著性影响因子;然后以主导立地因子及其组合作随机效应,建立基于立地随机效应的杉木多形立地指数曲线模型,通过模型选优对不同立地因子水平的立地质量进行评价;最后以K-means聚类划分立地类型组,解决复杂立地类型的模型应用问题,以提高立地指数曲线模型的适用性和准确性。
-
湖南位于中亚热带,地貌大部分为丘陵,呈现大陆性季风湿润气候,全年平均气温17.5 ℃左右,平均降水量1 200~1 700 mm,日照时长1 300~1 800 h,雨水丰富且热量充沛。研究区乔木树种以杉木(Cunninghamia lanceolata (Lamb.) Hook)为主,其次为马尾松(Pinus massoniana Lamb.)与拟赤杨(Alniphyllum fortunei (Hemsl.) Makino)等。主要小乔木与灌木有冬青(Ilex chinensis Sims)、木姜子(Litsea euosma W.W.Smith)、山茶(Camellia japonica L.)、杜茎山(Maesa japonica (Thunb.) Moritzi.)等。主要草本植物有狗脊蕨(Woodwardia japonica (L. f.) Sm.)、铁芒萁(Dicranopteris linearis (Burm.) Underw.)等。
-
以湖南丘陵平原区杉木人工纯林为研究对象,在湘乡、怀化、会同、株洲、永州、临湘、绥宁、桃源等26个县,设置样地(20 m × 30 m)共360块,记录相关立地因子,并对样地内活立木每木检尺。样地内每0.01 hm2选取最粗优势木1株,计算优势木平均高(H)。相关林分调查因子统计详见表1。
因子
Factors树高
H/m年龄
Age/a坡度
Slope/0海拔
Altitude/m土层厚度
Soil depth/cm平均值 Mean 10.0 15.0 23.5 252.2 72.4 标准差 Std. 3.7 5.4 8.8 89.2 22.2 最小值 Min. 4.2 8.0 4.5 97.0 24.0 最大值 Max. 26.3 49.0 44.0 500.0 150.0 Table 1. Statistics of stand factors for Cunninghamia lanceolata
-
选取如表2所示的影响杉木优势高生长的6个立地因子,根据《中国森林立地》相关标准进行分级,将海拔每100 m划分为一级,分析不同海拔的差异。
立地因子
Site factor符号
Symbol等级划分
Grade division海拔 Altitude HB 100 m为一级,共5级。 坡度 Slope gradient PD 平坡 缓坡 斜坡 陡坡 急坡 坡位 Slope position PW 阳坡 半阳坡 阴坡 半阴坡 坡向 Slope aspect PX 脊部 上坡 中坡 下坡 山谷 平地 土壤类型Soil type TL 红壤 黄壤 棕黄壤 土壤厚度 Soil depth TH 薄 中 厚 Table 2. The division of site factor grades
立地因子作自变量,各林分优势木平均高做因变量,运用数量化方法Ⅰ对杉木立地因子分别分析。基于方差分析中不同“Pr>F”大小,筛选显著因子并进一步得到主导因子。
-
为更准确地评价杉木立地质量,本研究考虑立地因子作随机效应对杉木立地指数模型的影响,随机效应包括了立地因子与其交互作用。非线性混合效应模型的形式为[19-20]:
式中:
$ {H_{ij}} $ 为第$ i $ 个立地类型下第$ j $ 个样地的平均优势高,$ {T_{ij}} $ 为第$ i $ 个立地类型下第$ j $ 个样地的林龄,$ {\varphi _{ij}} $ 为参数向量,$ {\varepsilon _{ij}} $ 是误差项,$ M $ 是立地类型数量,$ {n_i} $ 为第$ i $ 个立地类型的样地数,$ \beta $ 为($ p \times 1 $ )维固定效应向量,$ {b_i} $ 为($ q \times 1 $ )维随机效应向量,$ {A_{ij}} $ ,$ {B_{ij}} $ 为设计矩阵,$ D $ 为随机效应的方差—协方差矩阵,$ {R_i} $ 为立地类型内的方差—协方差结构,$ {\sigma ^2} $ 为方差,$ {G_i} $ 为描述方差异质性的对角矩阵,$ {\Gamma _i} $ 为描述随机效应自相关性的方差矩阵。构建非线性混合效应模型,需要对固定与随机效应参数进行构造。通常情况下对所有可能的参数考虑随机效应,但这会造成模型不收敛 [21-22]。为避免模型不收敛问题,本研究选择在1个参数上考虑立地的随机效应。其次,由于本研究中林分优势高与年龄不是重复调查数据,不存在样地内测量值之间的相关性。因此,假设误差项
$ {\varepsilon _{ij}} $ 服从正态分布。最后,本模型只考虑单个随机效应参数来确定随机效应参数方差,因此假定随机参数构造类型为无结构,并采用AIC、BIC、对数似然比(Log-likelihood)和确定系数
$ {R}^{2} $ 选择最优混合效应模型。AIC、BIC值越小,Log-likelihood和$ {R}^{2} $ 越大,模型的拟合效果越好。 -
基础模型不仅要能够很好描述林木优势高生长规律,还要具有生物学的可解释性[23-24]。其中立地指数曲线基础模型常为“S”形,本研究选择常用的立地指数曲线方程(M1~M8),拟合杉木林分优势高(见表3)。
模型
Model模型名称
Equation表达式
ExpressionM1 双曲线式(Hyperbolic curve) $ H=a + b/Age $ M2 抛物线式(Parabola) $ H=a + b\times Age + c\times {Age}^{2} $ M3 对数曲线式(Logarithmic curve) $ \mathrm{l}\mathrm{g}\left(H\right)=a + b\times \mathrm{l}\mathrm{g}\left(Age\right) $ M4 指数曲线式(Exponential curve) $ H=a/\left[1 + c\times \mathrm{e}\mathrm{x}\mathrm{p}(-b\times Age)\right] $ M5 对数双曲线式(Logarithmic inverse) $ \mathrm{l}\mathrm{g}\left(H\right)=a + b/Age $ M6 理查德式(Richards) $ H=a\times {\left[1-\mathrm{exp}\left(-b\times Age\right)\right]}^{c} $ M7 坎派兹式(Gomepertz) $ H=a\times \mathrm{e}\mathrm{x}\mathrm{p}\left[-c\times \mathrm{exp}\left(-b\times Age\right)\right] $ M8 单分子式(Mitscherlich) $ H=a*\left[1-b\mathrm{*}\mathrm{e}\mathrm{x}\mathrm{p}(-c\times Age)\right] $ ① $ H $:优势木平均高,$ Age $:林分年龄,$ a $、$ b $、$ c $:参数;$ H $:dominant height,$ Age $:Stand age,$ a $、$ b $、$ c $:Parameters to be estimated; Table 3. Candidate basic models
-
利用确定系数(
$ {R^2} $ )、预估精度($ P $ )、平均绝对误差($ MAE $ )和均方根误差($ RMSE $ )进行模型评价。式中:
$ {y}_{i} $ 为第$ i $ 个样地林分优势高实测值,$ {\widehat{y}}_{i} $ 为第$ i $ 个样地林分优势高估计值,$ n $ 为样本数,$ {t}_{\alpha } $ 为置信水平α=0.05时的$ t $ 分布值,$ p $ 为模型参数个数,$ \widehat{\stackrel{-}{y}} $ 为平均预估值。 -
林分优势木平均高受多种立地因子综合作用影响。根据优势木平均高与不同立地因子的相互关系,采用数量化方法Ⅰ对其进行显著性检验,结果(表4)表明:对优势木平均高具有显著影响的立地因子有海拔、坡度、坡向与土壤类型,其显著性顺序为土壤类型>海拔>坡向>坡度。
因子组 平方和 自由度 均方 F值 Pr>F 备注 海拔(HB) 191.602 6 4 47.900 6 4.672 6 0.001 1 显著 坡度(PD) 115.500 0 4 28.874 9 2.816 7 0.025 2 显著 坡位(PW) 49.216 6 5 9.843 3 0.960 2 0.442 2 不显著 坡向(PX) 140.354 3 3 46.784 7 4.563 8 0.003 7 显著 土壤厚度(TH) 10.787 2 2 5.393 6 0.526 1 0.591 3 不显著 土壤类型(TL) 199.622 6 2 99.811 2 9.736 5 0.000 1 显著 Table 4. Significance testing of site factors
-
利用 Forstat2.1软件对候选基础模型M1~M8进行估计,相关基础模型参数估计值、确定系数(
$ {R}^{2} $ )、预估精度($ P $ )、平均绝对误差($ MAE $ )及均方根误差($ RMSE $ )如表5所示。模型 Model a b c R2 P MAE RMSE M1 18.477 0 −115.872 0 — 0.424 3 0.971 2 7.534 8 2.770 6 M2 2.758 7 0.465 0 0.001 0 0.563 7 0.974 9 6.768 9 2.411 8 M3 0.089 4 0.767 6 — 0.515 6 0.968 4 32.432 1 9.694 0 M4 32.224 7 0.070 5 6.519 4 0.564 4 0.975 0 6.762 6 2.410 0 M5 1.319 3 −4.700 5 — 0.424 3 0.968 0 32.432 1 9.697 6 M6 794.671 2 0.000 3 0.809 2 0.559 8 0.974 7 6.784 5 2.422 4 M7 44.182 4 0.033 3 2.463 1 0.564 3 0.975 0 6.767 4 2.410 2 M8 2014.465 1 0.998 8 0.000 2 0.563 3 0.974 9 6.769 5 2.412 8 Table 5. The fitting results of candidate basic models
从8个候选基础模型(表5)拟合结果可知,这8个模型的拟合精度均较低(
$ {R}^{2} $ =0.424 3~0.564 4),也证明了区域性立地指数建模精度低的问题。其中,模型M4拟合效果最好,其确定系数($ {R}^{2} $ =0.564 4)与预估精度($ P $ =0.975 0)最大,平均绝对误差($ MAE $ =6.762 6)及均方根误差($ RMSE $ =2.410 0)最小。 -
以主导立地因子作随机效应,考虑立地单因素与多因素交互作用,构建立地指数混合模型。结合基础模型参数个数和随机效应因子组合类型,拟合所有参数及其组合形式,最优随机效应立地指数模型通过AIC和BIC等评价指标获取(表6)。
随机效应构造
Random effects最优参数组合
Combinations水平数
Levela b c AIC BIC Log-likelihood R² None — — 32.225 5 0.070 5 6.519 5 1 662.967 6 1 678.511 7 −827.483 5 0.564 4 HB a 5 29.936 5 0.072 1 5.785 2 1 643.977 3 1 663.407 7 −816.988 3 0.603 0 PD a 5 30.853 4 0.074 3 6.342 8 1 661.765 8 1 681.195 2 −825.882 4 0.578 6 PX a 4 32.224 3 0.070 5 6.519 3 1 664.967 9 1 684.397 7 −827.483 5 0.565 5 TL c 3 27.022 9 0.076 0 4.988 1 1 644.546 0 1 663.976 4 −817.272 8 0.599 8 HB*PD a 21 27.889 8 0.077 7 5.615 0 1 638.762 3 1 658.193 7 −814.381 1 0.635 3 HB*PX a 19 27.312 5 0.079 4 4.214 7 1 648.501 5 1 668.642 9 −1 019.250 8 0.604 8 HB*TL a 13 27.915 3 0.074 0 5.021 1 1 614.353 8 1 633.783 3 −802.176 4 0.659 2 PD*PX a 19 28.591 9 0.078 0 5.965 7 1 658.537 4 1 677.967 8 −824.268 4 0.595 5 PD*TL a 15 31.475 9 0.071 9 6.106 7 1 657.576 0 1 677.006 4 −823.788 0 0.600 5 PX*TL a 12 28.221 5 0.072 4 5.256 2 1 645.723 9 1 665.153 3 −817.861 3 0.568 1 HB*PD*PX a 52 21.760 2 0.100 6 4.894 9 1 608.572 6 1 628.002 9 −799.285 9 0.737 2 HB*PD*TL a 44 22.840 1 0.092 3 4.320 6 1 629.780 4 1 619.921 8 −821.890 2 0.706 2 HB*PX*TL a 42 20.847 9 0.098 3 4.099 7 1 597.599 4 1 617.029 8 −793.799 3 0.730 9 PD*PX*TL a 42 32.226 7 0.070 5 6.519 6 1 664.967 0 1 684.397 0 −827.483 5 0.566 3 HB*PD*PX*TL a 78 19.621 3 0.115 7 4.574 7 1 573.266 0 1 592.697 0 −781.633 1 0.808 9 Table 6. The fitting results of mixed effects models considering site effect
计算结果显示,除HB、PX、TL等单因子在其它参数组合的拟合效果较优外,受水平数影响,其它随机效应组合均只在渐进参数
$ a $ 上时,模型收敛。因此,含立地随机效应的杉木多形立地指数模型表达式为:式中:a,b,c为模型固定效应参数;
$ {\mu _i} $ 为随机效应参数;H为林分平均优势木高;Age为林分年龄。拟合多种随机效应因子组合类型后的结果如表6所示,AIC、BIC相对于基础模型M4都显著下降,Log-likelihood和
$ {R}^{2} $ 均大幅提高,这说明基于立地随机效应的混合模型明显优于基础模型。此外,混合模型拟合效果的好坏,取决于立地因子显著性的高低,立地因子越显著,相应随机效应组合类型的混合模型拟合结果越好。其中,海拔、坡度、坡向、土壤类型4个主导立地因子交互作用的混合模型AIC、BIC最低,Log-likelihood及$ {R}^{2} $ 最高。根据立地分类的原则与方法,4个主导立地因子排列组合可得到立地类型,综上所述含立地类型的混合模型为最优模型。 -
依据海拔、坡度、坡向、土壤类型4个主导因子,将研究区划分为78个立地类型,那么相应的混合模型随机效应参数有78个,势必会影响立地指数模型的应用。为了简化立地类型,将初始立地类型(ST)进行K-means聚类。参考森林立地分类的标准,确定系数≥0.99为聚类精度标准,合并得分值相近的立地类型为立地类型组(GST),使得本研究区的立地类型聚类为11种(表7)。
立地类型组
Group of site types样本量
Sample size立地类型数
Site type quantityⅠ 50 5 Ⅱ 52 12 Ⅲ 8 5 Ⅳ 95 11 Ⅴ 59 8 Ⅵ 12 4 Ⅶ 18 10 Ⅷ 16 8 Ⅸ 12 2 Ⅹ 15 5 Ⅺ 23 8 Table 7. Classification of cluster with site types
将聚类后的立地类型组(GST)作为随机效应构建立地指数非线性混合模型,利用AIC、BIC、Log-likelihood及
$ {R}^{2} $ 等4个指标进行模型选择(表8),并与基础模型(None)、初始立地类型(ST)模拟结果进行比较。如表8所示,考虑立地的随机效应后,模型确定系数从0.564 4提高到0.808 9~0.811 7,其中基于立地类型组的混合效应模型模拟精度最高($ {R}^{2} $ =0.811 7,Log-likelihood=−704.987 9)。因此,基于立地随机效应的立地指数曲线模型可以极大提高模型精度,同时利用K-means聚类划分立地类型组的方法,不仅保证了预估精度,而且还简化了立地类型,提高立地指数模型的实用性。随机效应
Random effecta b c AIC BIC Log-likelihood R² None 32.225 5 0.070 5 6.519 5 1 662.967 6 1 678.511 7 −827.483 5 0.564 4 ST 19.621 3 0.115 7 4.574 7 1 573.266 0 1 592.697 0 −781.633 1 0.808 9 GST 21.253 8 0.104 5 4.444 4 1 419.976 0 1 439.406 0 −704.987 9 0.811 7 Table 8. Model evaluation
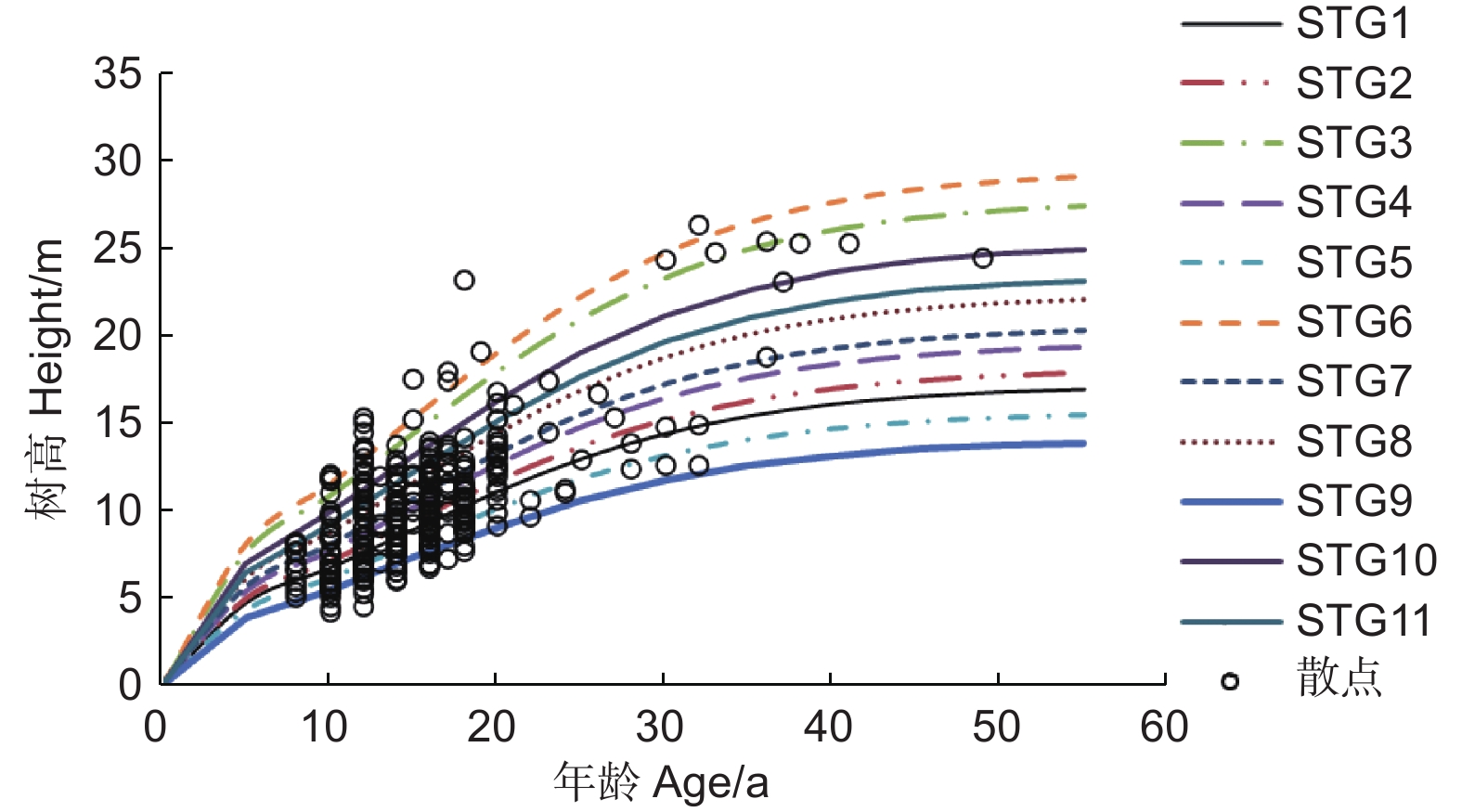
利用该模型绘制湖南丘陵平原区杉木多形立地指数曲线(图1)。图中展示了不同立地类型组的立地指数曲线图,各立地类型组的模型模拟效果均较好。
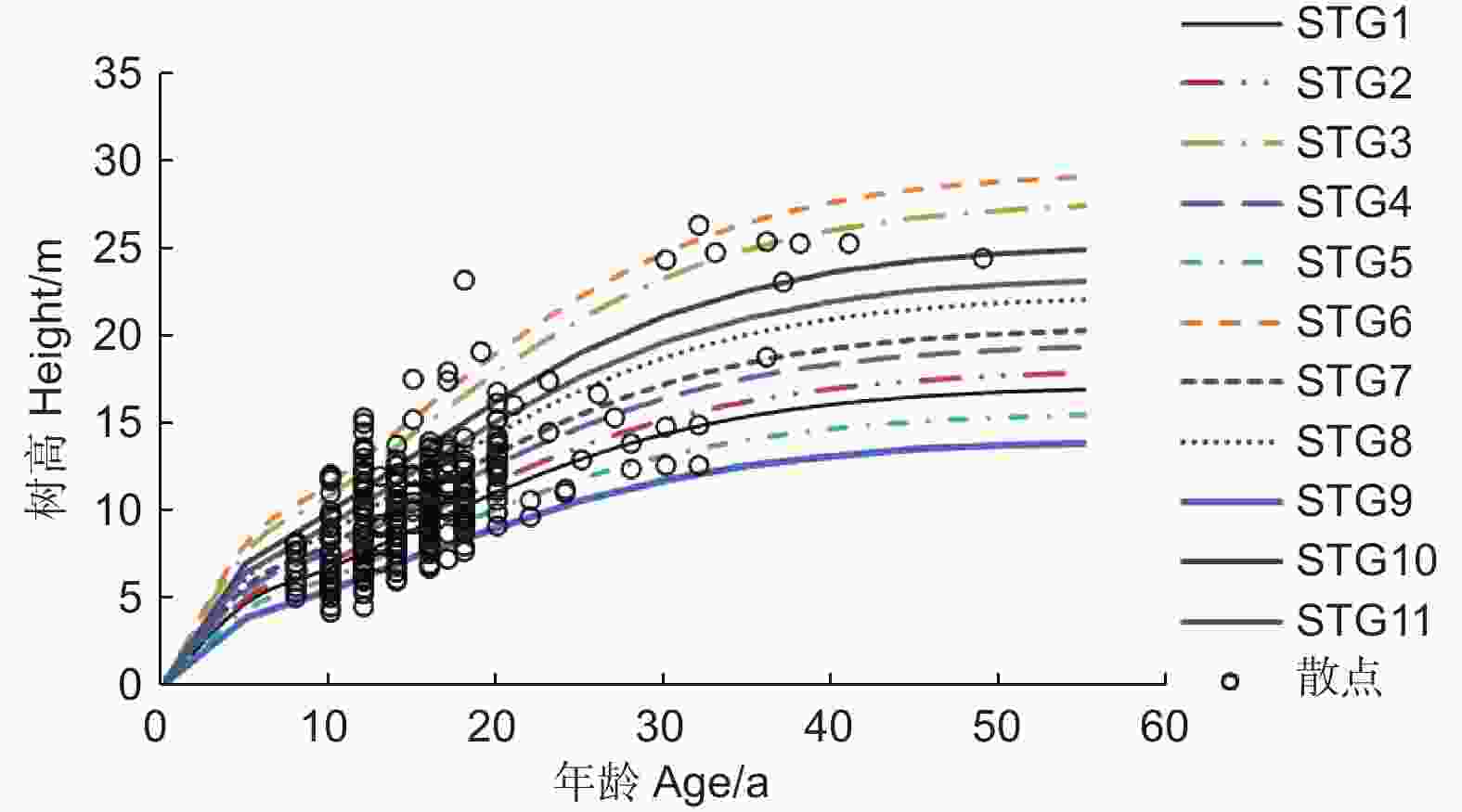
Figure 1. Polymorphic site index curve
-
林分优势高生长受林分密度影响很小,是同龄林立地质量评价采用最广泛的指标,但关于林分优势高的定义及测定标准并不一致[25]。赵美丽等[26]对樟子松(Pinus elliottii Engelm.)同龄林最高、最粗木平均优势高的相关性、稳定性研究后认为,最粗6株木法能科学得到林分优势高,该方法具有简易、稳定的优点,所以本研究以每100 m2选择1株最粗木的方法计算平均优势高。
在森林立地分类与评价的因子中,地形属间接因素,但综合反映着气候和土壤特性。本研究在进行显著性研究中用数量化方法I,以分析不同立地因子对杉木优势高生长的影响,结果表明,海拔、土壤类型、坡向、坡度与杉木优势高生长有强相关性。不同立地因子对优势高生长的影响也不同。产生显著性差异的原因有以下几点:从海拔来说,南方丘陵平原地区热量和降水量的垂直分异总的来说决定了研究对象的生长与分布,海拔为一个主要因素。从土壤类型与坡度来说,杉木对土壤湿度、养分、通气性等要求较高,杉木生长由土壤类型的差异直接影响,坡度间接表现土壤特性。从坡向来说,不同坡向热量光照差异,对杉木不足以引起其生长的很大差异,故坡向相比较而言,显著性影响要低于土壤类型、海拔,但高于坡度的影响作用。王冬至等[27]在研究塞罕坝华北落叶松(Larix principis-rupprechtii Mayr)人工林地位指数模型时,将林分优势高与不同立地因子进行相关性分析,发现林分优势高与立地因子显著相关。
基于林分优势高-年龄关系的立地指数,已成为表征森林立地生产力的一个重要参数,应用该方法的前提在于导向曲线具有较高的模拟精度。然而对于某一特定的树种,导向曲线的形状会因气候、土壤、地形等的不同而有所变化,使用同一导向曲线模拟树高生长必然会造成较大误差[28]。而混合模型在估计总体的平均效应和个体差异上具有独特优势,可以通过多参数方法构建立地指数模型[29],有利于增加模型的评估精度。Wang等[30]利用哑变量与混合模型法分别模拟火炬松(Pinus taeda L.)树高生长,最终表明混合模型方法准确性更好。因此,为了解释不同立地水平的优势高生长差异,本研究采用单水平的非线性混合效应模型进行立地随机效应模拟,确定系数(
$ {R}^{2} $ )从基础模型拟合效果的0.424 3~0.564 4提高到0.565 5~0.808 9,以立地因子及其组合作随机效应的混合模型对比基础模型优势显著。本研究以K-means聚类为基础,将复杂的立地类型(ST)聚类划分成立地类型组(GST),并在立地指数模型中考虑GST为随机效应,构建多形立地指数模型(
$ {R}^{2} $ =0.811 7)。此方法较原来基础模型极大提高了模型预估精度,并且验证了立地类型聚类构造随机效应的方法具可行性。 -
本研究采用非线性混合效应模型方法,构建了含立地随机效应的湖南丘陵平原区杉木多形立地指数曲线模型,利用Forstat求解模型参数,得出如下结论:海拔、坡度、坡向与土壤类型是影响湖南丘陵平原地区杉木优势高生长的显著性因子,以显著性因子及其组合作随机效应可以显著提高立地指数建模精度,且包含立地类型的混合模型拟合精度最高,拟合精度的高低与主导立地因子的显著性紧密相关;以K-means聚类将杉木78个初始立地类型划分为11个立地类型组,包含立地类型组的混合模型在保留预估精度的前提下提高模型实用性。因此,基于立地随机效应的多形立地指数模型可以显著提高建模精度,也为区域性复杂立地类型的立地质量评价提供了思路与方法。
Polymorphic Site-Index Model with Site Mixed Effects for Chinese fir Plantations in Hunan Hilly Plains
- Received Date: 2022-05-23
- Accepted Date: 2022-06-15
- Available Online: 2022-10-20
Abstract:























































 DownLoad:
DownLoad: