


-
近年来无人机遥感技术发展迅速,轻小型无人机因其获取影像机动灵活、影像分辨率高等优势,成为传统航空摄影测量手段的有效补充[1],为林分冠幅信息的提取提供了有力的技术支持。冠幅提取的方法主要有面向对象法、分水岭分割法、专家分类法等。吴见[2]等通过基于边缘的算法对快鸟全色影像中的植被区域进行二级分割,利用光谱、形状和纹理特征组成的空间特征对退耕还林地的树冠信息进行了提取,总体精度达到84.67%。王茹雯[3]等利用面向对象技术对延庆县试验地的侧柏树冠信息进行了提取,监测平均精度达到80.02%,针叶林提取精度高于阔叶林。Wang Le[4]等采用分水岭分割法,在树冠中心点周围描绘树冠轮廓,以及Song C[5]等利用IKONOS影像, 通过半方差函数计算冠幅, 均取得了较好的精度。大部分研究者仅进行了林木冠幅信息提取在方法技术上的探究,而将冠幅提取方法进一步用于森林调查中,探究与林木胸径、林分蓄积量之间的相关关系,研究还较少。
随着遥感事业的大力发展,利用遥感技术估测森林蓄积量的研究不断深入,大多数研究者利用遥感数据,结合少量样地调查数据,建立回归模型的方法[6-9]估测森林蓄积量,少部分研究者利用LiDAR、雷达等仪器,获得林分树高等林分结构参数,直接计算森林蓄积量[10-12],或者融合主被动遥感获取的影像,以及分别提取主被动遥感中的遥感信息参数进行森林蓄积量估测[13-16]。现今遥感估测蓄积量方法主要是基于大尺度范围,虽省时省力,但难以做到精细化。
针对以上研究空缺,本研究以无人机高清影像为数据源,在前人研究的基础上,结合样地实地调查数据,对高清影像进行多尺度分割,提取杨树单株林木冠幅,通过模型得到林木胸径,建立冠幅-胸径线性相关模型,进而估测出林分蓄积量,并进行相关性分析与精度评价,旨在为进一步改进和完善森林蓄积量无人机遥感监测体系提供理论参考。
HTML
-
东台林场位于江苏省东台市,地理坐标介于120°47′11″~120°52′0″E,32°53′30″~32°51′17″N,处于亚热带和北温带过渡区,季风显著,四季分明,年均气温15.0℃,雨量充沛(年均降水量1 061.2 mm),地势平坦,近海无山,土壤肥沃湿润,极适合杨树生长。东台林场现有树种达200种,木材总蓄积量约5万m3,主要经营树种为杨树(Populus simonii Carr.)、水杉(Metasequoia glyptostroboides Hu et Cheng),林场内95%林分为人工纯林,林下植被主要有:金银花(Lonicera japonica Thunb.)、金钟(Forsythia viridissima Lindl.)、小叶女贞(Ligustrum quihoui Carr.)、木香(Rosa banksiae Ait.)、枸杞(Lycium chinense Mill.)等。
-
通过小班矢量等先验数据,于东台市东台林场内的杨树人工林中随机布设了79块样地。每块样地的面积大小为0.067 hm2,对样地中的林木进行每木检尺,起测径阶为5 cm,并用罗盘仪、激光测距仪记录每株林木的方位角与水平距,以便在arcgis软件中准确复位。根据胸径选取样地中3~5株平均木与优势木,借助测高器、皮尺,测量树高(H)、东西冠幅(CWEW)和南北冠幅(CWSN),并计算平均冠幅(CW),共得到235株杨树样木数据。同时,记录样地的GPS坐标、林分年龄(t)、林分密度(株·hm-2),剔除异常数据后,将样地数据整理并汇总于表 1。
变量 量测数量 平均值 最大值 最小值 标准差 年龄/a 79块样地 14 23 4 6.79 胸径/cm 1 708株 28.35 5.7 5.5 8.12 树高/m 235株 274 1.71 1.2 6.44 东西冠幅/m 235株 7.51 5.7 2.1 2.38 南北冠幅/m 235株 6.41 4.5 2 2.37 密度/(株·hm-2) 79块样地 324 645 120 135 Table 1. Field investigation data summary
-
样地调查的同时,进行无人机遥感影像采集,采用的无人机是数字绿土八旋翼无人机,无人机搭载了一个CCD相机。将采集的高分影像进行拼接、几何校正、正射校正、最终得到的影像分辨率为0.15 m。
-
采用面向对象法对林木冠幅进行分割和提取[17-18]。利用arcgis软件,用样地GPS信息建立样地边框,通过边框裁剪出样地内的无人机影像,将影像输入Definiens eCognition 8.0软件,进行面向对象多尺度分割。影像分割尺度的不同,产生的对象大小也不同,尺度太大会使提取的冠幅中包含空地、阴影等信息,尺度太小则可能使单株林木冠幅过于破碎;同时,平滑度与紧致度的权重也很大程度上影响分割效果[19]。本研究于8~20等多个尺度之间,以及不同紧致度、平滑度间进行多次试验,最终选取的分割尺度为10,平滑度0.1,紧致度0.5。影像分割完成后,对各样地分别提取出冠幅信息。分析面向对象分割单元发现,对象单元中林木枝叶的亮度值较高,将亮度值作为提取冠幅的指标。本研究应用阈值分类法,利用亮度值、相邻性指数进行组合,描述树冠类信息,针对79块样地,各设定相对应的阈值组合类型。提取出林木冠幅矢量信息之后,将影像分割提取杨树平均冠幅与对应林木实测平均冠幅进行分析与误差修正。
-
众多研究表明[20-24],林木胸径与冠幅具有显著的正相关性,且胸径生长与冠幅增加的相关规律不受立地条件与林龄差异的影响[25]。本研究从235株样木中随机提取200株杨树的胸径、冠幅进行模型构建,剩余35株样木作为模型检验样本。根据散点分布图,选择一元线性模型、对数曲线模型、二次曲线模型、三次曲线模型、幂函数曲线模型、指数曲线模型、logistic模型等7种常见模型进行回归分析,并选取出相关系数最大,且F值最小的模型。
-
利用一元材积表计算杨树单株材积,查询苏北地区杨树一元材积表,研究区杨树的一元材积经验式为:
将影像提取的修正后的冠幅代入冠幅-胸径模型,算出杨树胸径,进而得到杨树单株材积,根据影像分析出的林木株数,将样地所有杨树单株材积累加,即可得到样地蓄积量。
2.1. 数据来源
2.1.1. 样地调查数据
2.1.2. 遥感数据
2.2. 研究方法
2.2.1. 林木冠幅提取
2.2.2. 胸径冠幅模型选择
2.2.3. 蓄积量推算
-
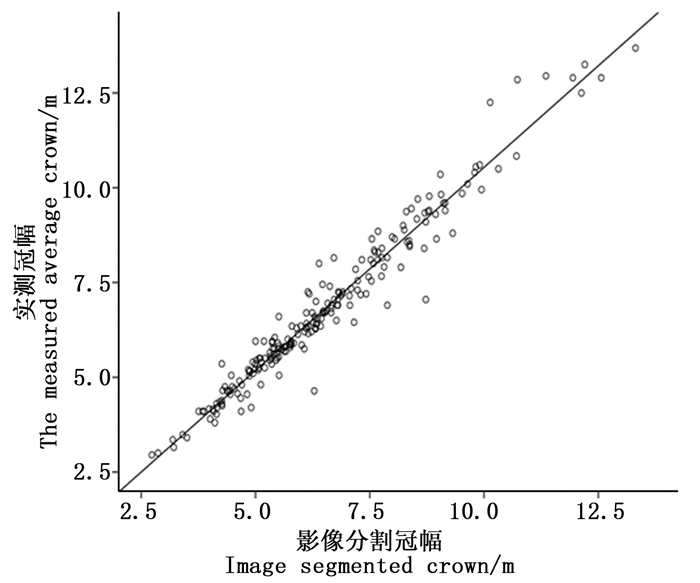
利用arcgis10.1切割样地影像,在Definiens eCognition 8.0中分别设置提取参数,对各样地进行冠幅提取,图 1所示为第35号样地分割效果图,该样地的分割尺度为10,平滑度0.1,紧致度0.5,选取亮度值为110~127的尺度进行提取冠幅提取。从图中可以看出,样地内冠幅基本能清晰直观地分割出来,分割效果良好。但研究区林分郁闭度较高,平均郁闭度达0.7,林木冠幅重叠区域较多,无人机航拍影像难以区分重叠部分冠幅。将200株有实测平均冠幅($ \overline {{\rm{CW}}} $)的样木与影像提取平均冠幅($ {\overline {{\rm{CW}}} _{\rm{s}}}$)进行比较分析,以$ {\overline {{\rm{CW}}} _{\rm{s}}}$为横坐标,$ \overline {{\rm{CW}}} $为纵坐标,绘制散点图如图 2所示,由散点图可知,影像分割平均冠幅与实测平均冠幅形成明显的一元线性相关关系。由图 1、图 2可以看出,影像分割冠幅整体偏小,利用实测平均冠幅数据对程序自动分割平均冠幅进行修正,将200份样木数据输入SPSS进行拟合,一元线性方程拟合结果如表 2、表 3所示,相关系数R2为0.956,拟合效果良好。得到的修正模型表达式为:

Figure 1. Crown segmentation image of No. 35 plot
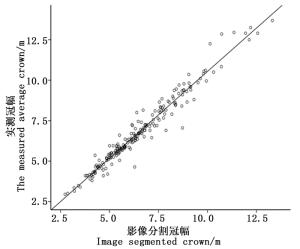
Figure 2. The correlation of image segmented average crown and measured average crown
R R2 调整R2 估计值的标准误差 0.978 0.956 0.956 0.444 Table 2. Model fitting results
项目 平方和 df 均方 F Sig. 回归 906.046 1 906.046 4 292.413 0.000 残差 41.794 198 0.211 - - 总计 947.840 199 - - - Table 3. Analysis of variance
-
利用SPSS统计软件,选取7种回归模型,以杨树实测冠幅为自变量,胸径为因变量,建立估测模型,结果如图 3、表 4所示。
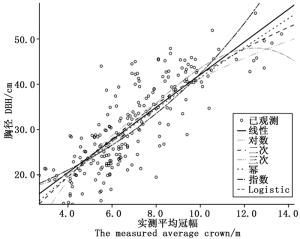
Figure 3. The curves of crown and DBH correlation
方程 模型汇总 参数估计值 R2 F df1 df2 Sig. 常数 b1 b2 b3 线性函数 0.753 449.360 1 198 0.000 1.102 3.604 - - 对数函数 0.658 420.278 1 198 0.000 -15.483 24.652 - - 二次函数 0.729 229.852 2 197 0.000 -0.075 5.366 -0.115 - 三次函数 0.711 160.860 3 196 0.000 21.595 -4.156 1.170 -0.054 幂函数 0.642 391.662 1 198 0.000 6.382 0.813 - - 指数函数 0.631 372.299 1 198 0.000 13.221 0.116 - - Logistic 0.631 372.299 1 198 0.000 0.076 0.890 - - Table 4. Parameter summary of curve estimation model
由表 4可知,一元线性函数相关系数R2最大,且其剩余标准差最小,选取该模型构建胸径、冠幅模型,表达式为:
式中,D表示胸径,$ \overline{C W}$表示平均冠幅。
将剩余的35株样木测量数据用于最优模型适用性检验,利用均方根误差RMSE、系统误差TRE、平均相对误差MPE(公式4~6)三个评价指标进行模型检验,以RMSE≤5,TRE≤±5%,MPE≤±10%,作为检验标准[26]。
经计算得:TRE=-0.190 3%,MPE=0.883 3%,RMSE=1.577 cm,预测值减去实测值即可得到残差,残差分布图如图 4所示。
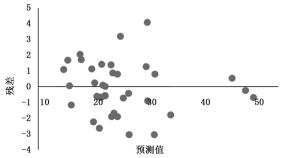
Figure 4. Residual distribution of crown and DBH correlation model
由检验结果可以看出,预测值残差在-3.0~4.1cm之间,且误差指标TRE、MPE、RMSE(分别为-0.190 3%,0.883 3%,1.577 cm)均小于检验标准,说明模型拟合效果良好,可利用(3)式,通过杨树冠幅,计算研究区杨树胸径。
-
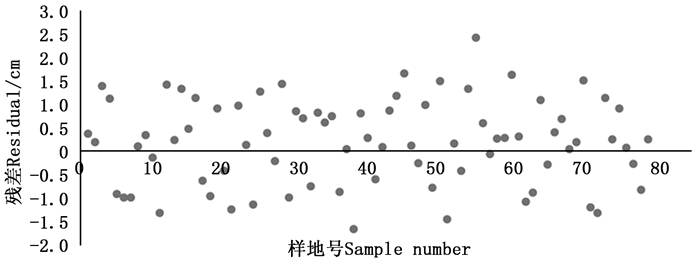
通过无人机影像得到样地林木平均冠幅长度,由方程(2)、(3)得到林木胸径,代入杨树一元材积经验表达式即可得到杨树材积,累加后得到样地蓄积量。将79块样地实测胸径得到的蓄积量(V1)与通过冠幅-胸径模型得到的蓄积量(V2)进行对比,相减后得到残差值,残差分析图如图 5所示。对两种方法得到的蓄积量通过SPSS软件进行双侧T检验,检验结果列于表 5,从表中可以看出,sig值>0.05,说明两组数据差异不显著,表明两种方法得到的蓄积量之间相关关系强。
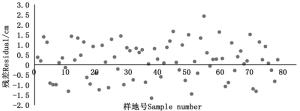
Figure 5. Residual distribution of volume
项目 均值 标准差 均值的标准误 差分的95% 置信区间 t df Sig.(双侧) 下限 上限 实测蓄积-预测蓄积 0.196 0.906 1 0.101 94 -0.006 6 0.399 3 1.92 6 78 0.058 Table 5. Result of Student's t test
3.1. 林木冠幅分割
3.2. 胸径冠幅模型构建与验证


3.3. 蓄积量推算及精度分析
-
本研究采用面向对象法,自动分割并提取了杨树林木冠幅信息,提取效果良好,对比200株杨树影像提取平均冠幅与实测平均冠幅,发现影像提取平均冠幅总体偏小,这是由于无人机垂直获取影像,难以分辨重叠部分冠幅。通过实测冠幅建立修正模型,对影像自动提取平均冠幅进行修正,模型公式为: $ \overline{C W}=1.072 \times \overline{C W}_{s}-0.178$。影像分割过程中经过多次试验,发现该地区最适宜的冠幅分割尺度为10,平滑度0.1,紧致度0.5。由于研究区域较广,且林分龄级不一,郁闭度差异较大,林分间林相存在较多差异,难以找到一组通用的提取参数,所以对各样地分别提取林分冠幅。选取亮度平均值作为提取指标,提取结果表明,研究区内杨树冠幅亮度值在105~145之间,而如何得到大尺度范围内统一的提取参数,还需进一步研究。
通过实地测量杨树胸径、平均冠幅,并绘制成散点图,通过曲线模型拟合,发现该地区杨树胸径与平均冠幅成线性相关,通过SPSS软件进行模型构建,得到的胸径-冠幅一元线性模型相关系数为0.75,公式为:D=1.102+3.604$\overline{C W} $。利用无人机高分影像,得到修正后的平均冠幅,代入相关关系模型,即可得到林木胸径。
利用影像提取平均冠幅通过相关关系推算得到的蓄积量与样地实测胸径估算的蓄积量两组数据进行双侧T检验,检验结果sig=0.058>0.05,表明两组数据差异不显著,相关性较强。利用影像提取林木平均冠幅,通过冠幅-胸径相关关系模型得到林木胸径,进而推算林分蓄积的方法可以满足森林资源调查精度要求。
本研究充分利用了无人机高分影像分辨率高、椒盐噪声少、形状纹理信息丰富,且时效性强等特点,自动分割提取了杨树林木冠幅,并通过相关性分析建立冠幅-胸径模型,进而推算样地林分蓄积量,为无人机森林蓄积量调查技术提供了方法参考。
 DownLoad:
DownLoad: